

The last couple of weeks I was a little bit geeking into programming languages, distributed systems and databases. It was such a fascinating journey, I learned a lot. So, I decided to try documenting it here and see how it goes.
Basically, I’m dreaming to discover or implement a better modern SQL replacement, that could run smoothly on distributed backends and solve all the problems haha!
This post is about motivation, inspiration and where I’m currently stuck (hoping to find new ideas). In the follow-up posts, we’ll explore more technical details.
Data pipelines world
Over the last 5.5+ years at Google and X, I’ve been working on an endless amount of data pipelines (e.g. ETL-style), where in most cases, everything boils down to:
- Connecting to various data sources (databases, pub/sub topics, other APIs).
- Transforming the data, and implementing your business logic (e.g. computing earnings for users in the case of Google Ads). This could also be computation-heavy stuff like ML models inference, processing bees buzzing audios, etc.
- Loading results somewhere, or triggering APIs.
I’ve been mainly using FlumeJava (also C++) and Apache Beam Python, but there’re also many similar frameworks. If you have enough computing resources, processing petabytes of data is just a piece of cake. So much power in these technologies!
One thing that bothers me is just the amount of boilerplate. Just look at this Java code:
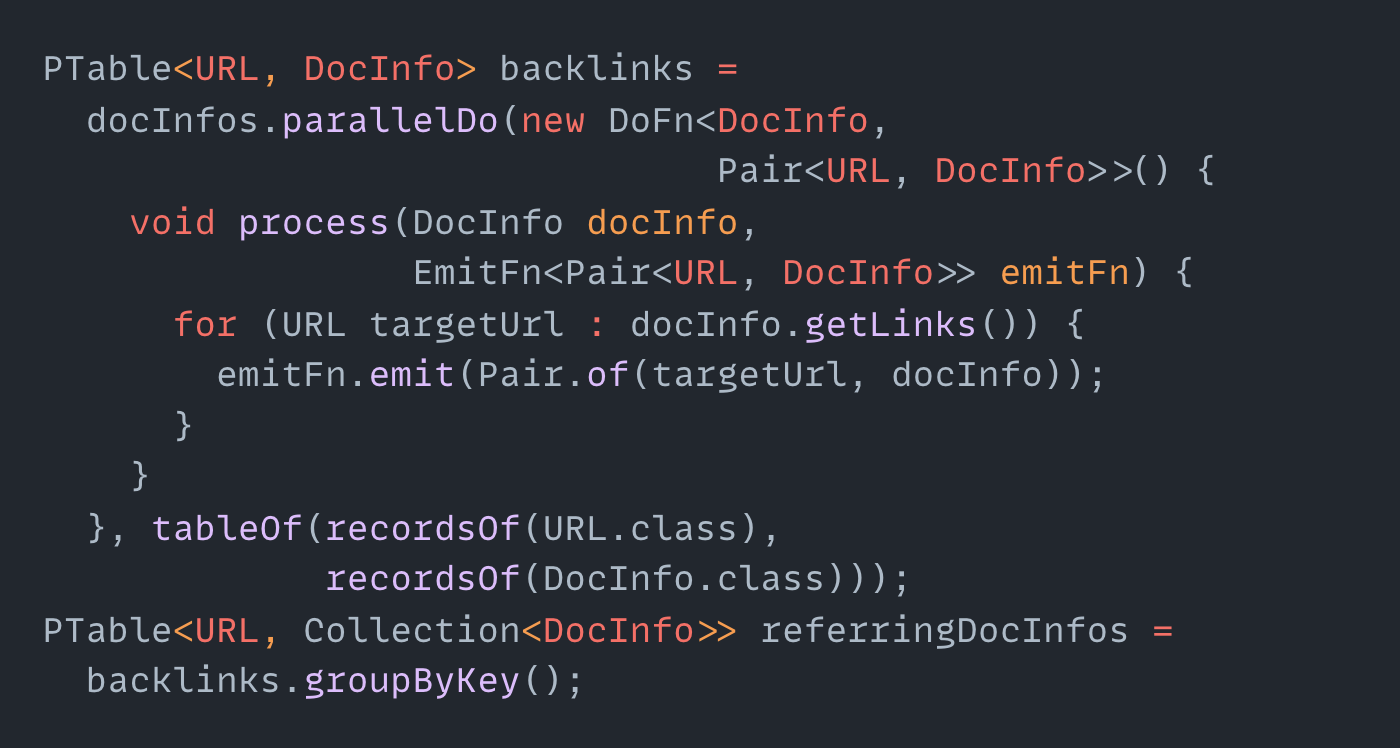
This is without imports, dependency injections, etc.
Productivity of SQL
The same logic above could be expressed with just a few lines of SQL:
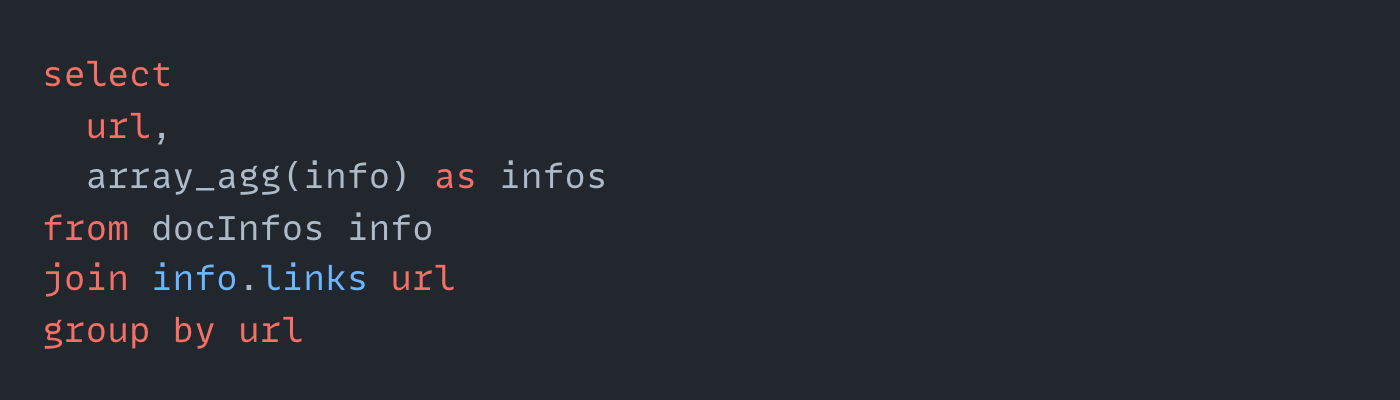
At some point I encountered some piece of code, which had almost 40 lines in Java, essentially doing something like "WHERE value > 10" would be in SQL.
Python is much more concise than Java, but it’s still not fantastic. It feels like you’re always writing some wrappers on top of some underlying logic (e.g. using GroupByKey primitives, etc), instead of focusing on the logic itself.
At the same time, SQL engines (e.g. BigQuery) are quite powerful these days. You can connect to multiple input data sources, you can create your own SQL functions, can call APIs, can even train simple ML models or process geo data. You can write 10 lines of code, hit CTRL+ENTER and thousands of workers would process your data in seconds. There’s also this bit of interactivity when working with the data. You can just add LIMIT 10 to any query, it’s much quicker to implement than when you have to compile Java/Python and run it against some fake data, or it takes a lot of time for workers to roll out.
There’re also solutions like dbt or DataForm that make your life simpler. You can split your code into modules, run tests for it, etc.
So, I became a really big fan of SQL. I hate writing boilerplate! SQL makes me super productive in the world of data. So, I started pushing all solutions to use SQL wherever possible!
The dark side of SQL
I’ve written a lot of SQL. I consider it my favourite language haha.
I stretched SQL quite a lot to make it look like a normal language:
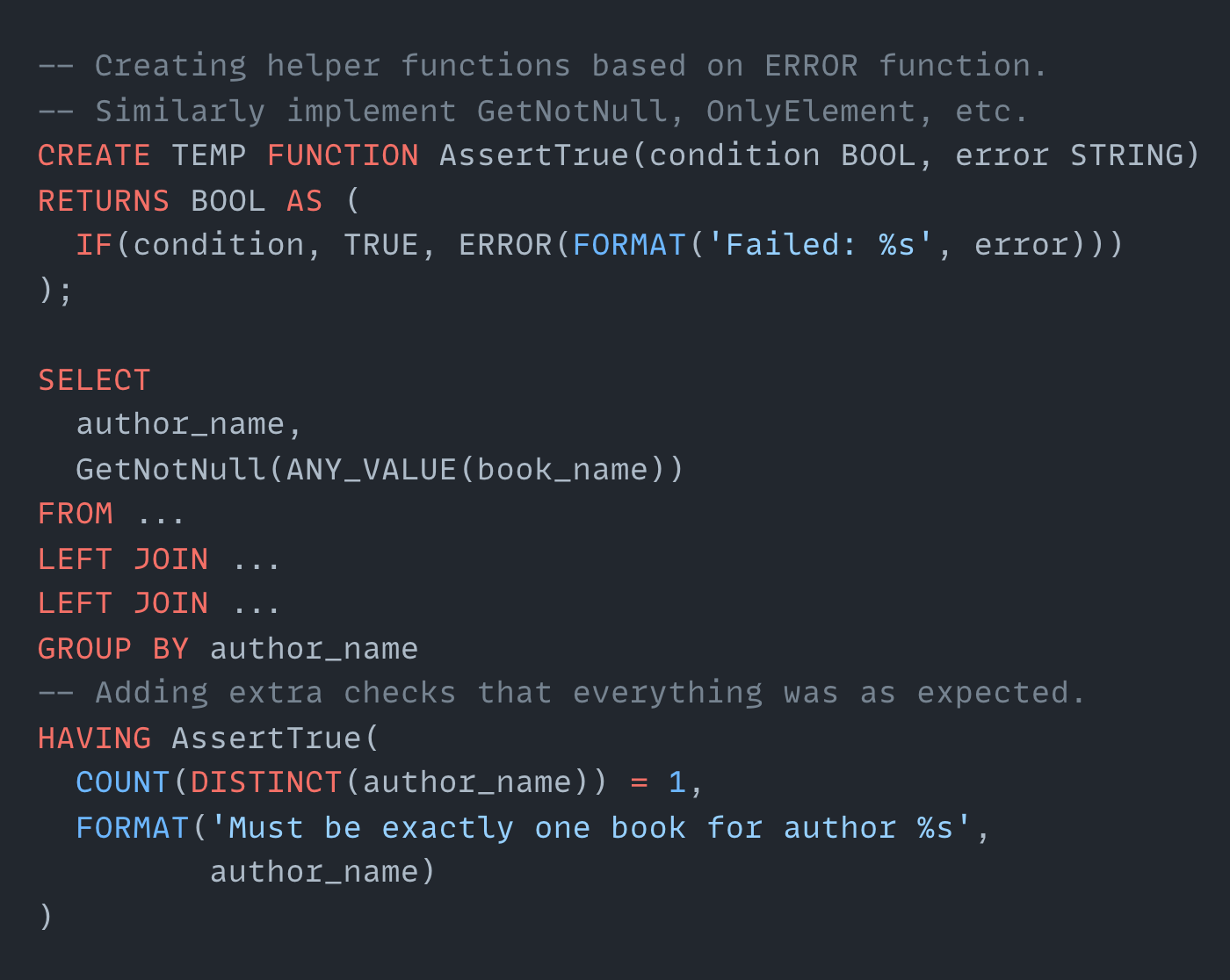
Imagine SQL of the future could do something like “please do the join, but make sure you’ll find only one element”. It could either be expressed using a strong type system or some other mechanism, that would be neat! I would use this language every day.
I understand why people hate SQL and totally could relate to that. It’s fairly hard to compose. It’s quite error-prone, it’s easy to make a mistake when doing joins, for example, your rows would expand, or you get some nulls that are not expected etc. “It feels like you’re writing a Pascal code and not a modern language” (Dan Abramov).
See more arguments against SQL:
- https://www.edgedb.com/blog/we-can-do-better-than-sql#critique-of-sql
- https://www.scattered-thoughts.net/writing/against-sql — this one I found a few days ago. It resonated with me deeply on many levels. Feels like it was written for me. It gives a lot of practical advice on how to create a SQL of the future.
Also, SQL syntax is very different on different platforms, sigh.
I wish there was a modern lean language that can describe pure logic of data flow, that could compile into distributed pipelines.
Implementing microservices
We have a joke that the majority of work at Google is simply moving one proto into another proto. I think the same applies to JSON to JSON. The majority of microservices are just about taking the input message, doing some business logic, maybe talking to a database, maybe checking permissions, and then returning a response message. All of that is written in Java, Python, Go, NodeJS, or whatever. And it’s again so much boilerplate!
Imagine there was a language that allows writing you some pure logic, describing the flow of data declaratively. I think Elixir, Haskell, and OCaml are doing here relatively well, but I think this SQL of the future could do an even better job for this use case.
I’m a big fan of GraphQL (in 100 seconds) for its simplicity. To me, it’s like a subset of SQL with a simpler syntax. There’s a really cool product called Hasura GraphQL (in 100 seconds). Basically, it can sit on top of your database and provide GraphQL API to the users. It handles permissions, etc.
“The most common error of a smart engineer is to optimise something that should not exist.” Elon Musk. So in certain cases, you can avoid creating microservices by leveraging solutions like Hasura. For example, I moved all the business logic (written in SQL) into logical views and materialized views, and then simply exposed those to the clients with Hasura.
Managing this backend was 100x simpler than if I had something self-written in Go or Python. There are also now companies that provide real-time materialized views (like Materialize or ksqlDB).
I believe real-time materialized views are the future! Happy the world is moving in that direction. Check out these fundamental videos (super old but fundamental) by Martin Kleppman:
💡 Turning the database inside out – really good talk
Also this one: Transactions: myths, surprises and opportunities.
Anyways, the main bottleneck is SQL again. It would so much better to write your business logic with something modern and expose it via logical views or materialized views to the world. Or even transpile it into some Go/Rust or whatever, if you wish that way.
Inspiration
Let's have a look into existing languages and libraries and see what we could borrow from them. Or maybe they could solve our problems completely?
ReScript/ReasonML, OCaml, F#
Ability to pipe everything. Everything is just an immutable chain of operations. Structural pattern matching. Concise syntax. Type inference from OCaml is really good, it has strong sound types, but you see them only when they are needed. Check out ReScript (it’s like OCaml with JS flavour).

Elixir, Erlang OTP
Piping everything, pattern-matching, phenomenal distributed engine model.
The ruby-inspired syntax for hipsters 🙂
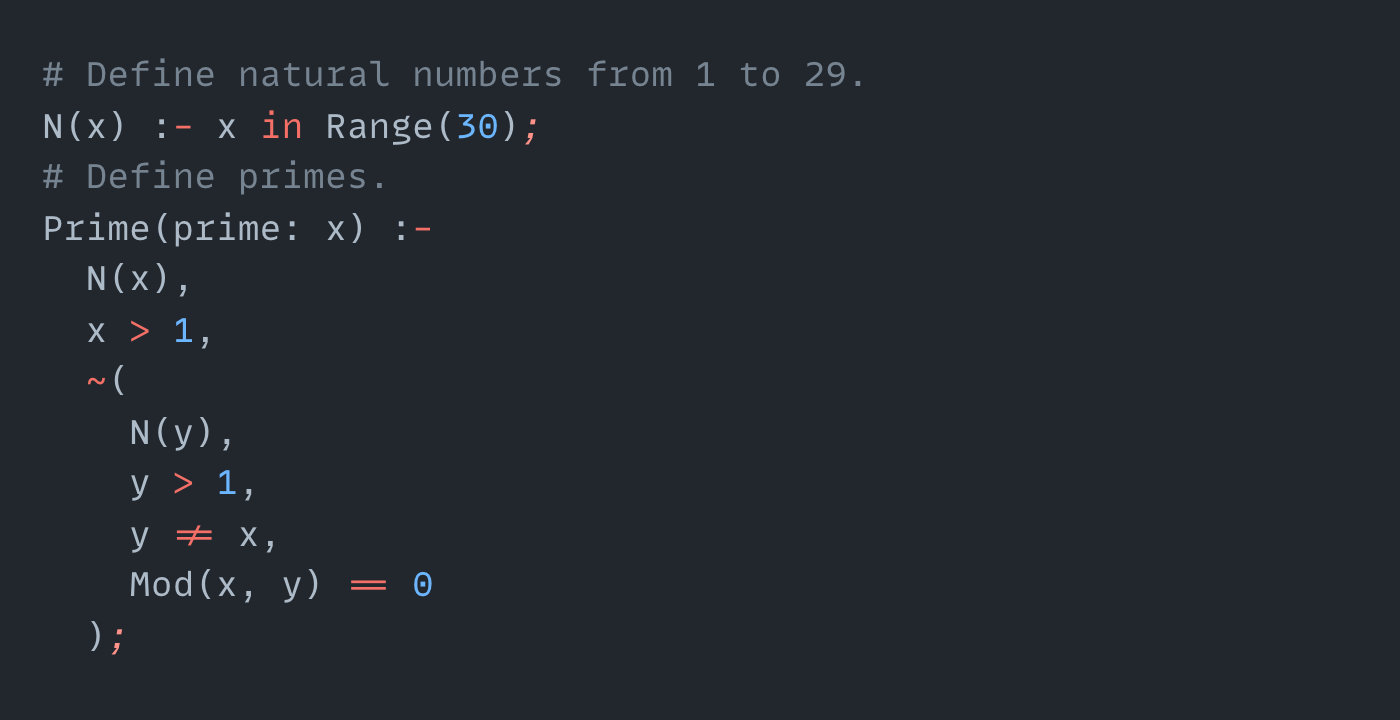
Datalog, Logica, Yedalog
Really cool prolog-inspired language describing pure logic.
Yedalog - we have this at Google, and it’s my initial inspiration.
Logica.dev - a datalog, compiling into BigQuery SQL, SQLite and others.
While it’s really really cool language, I wish it was a bit more user-friendly. I don’t see people easily adopting this to implement map-reduce pipelines and microservices.
Haskell Lenses / Optics
Optics (and its predecessor Lenses - thanks Tiziano Santoro for telling me about it) are amazing libraries to manipulate data. We should achieve this simplicity of resulting code and type safety in DreamQL while leveraging distributed backends. See the nice intro video.
Jaql
Jaql - a functional data processing and query language, it’s great for processing a bunch of JSONs. Everything is a chain. Compiles to Hadoop. We basically need something like that, but modern.
PRQL
PRQL - more composable SQL alternative, transpiles to SQL, written in Rust. Focused on analytic queries first. You can pipe everything. Integration with dbt! It’s almost exactly what we need (thanks Wojtek Czekalski for showing this to me). I'd like to have something like that, but with more GraphQL/ReScript syntax with figure brackets and pipes. Also extendable with WASM. But it's on of the best candidates so far!
GraphQL
This one is very good, minimalist query language. Imagine having GraphQL for data pipelines, where you can also chain your operations, describe logic, parsing unstructured text. That’s my dream!
JQ
JQ is a lightweight command-line JSON processor. We should be able to parse JSONs like we can do with JQ, with similar minimal readable syntax (thanks Michal Kazmierski for recommending).
LINQ / Java Stream API / PyFunctional / Python Pandas
We should have similar functions to transform the data effectively. Also, this feels like a wrapper over logic, e.g. you call the groupBy function and pass a ton of stuff inside (e.g. in Python Pandas). It feels like we need to have a way to express the logic directly, without wrappers.
Neo4j Cypher
Cypher is a query language for graph databases. I love their approach to joins. They call it matching:

EdgeQL from EdgeDB
EdgeQL from EdgeDB also is quite nice! I think there’s definitely a demand for the better SQL of the future (thanks Alexander Cheparukhin for recommending it).
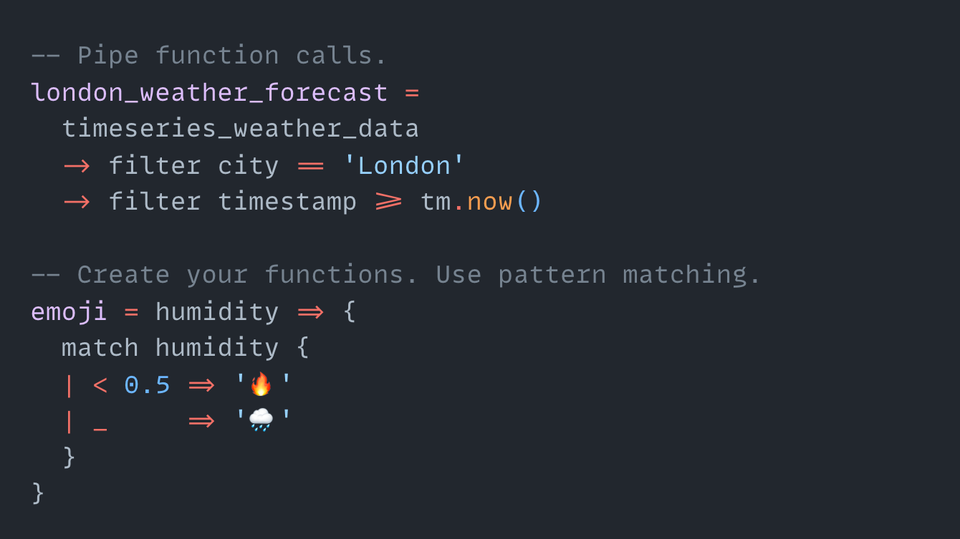
DreamQL Design
This is a sneak peek into the DreamQL syntax:
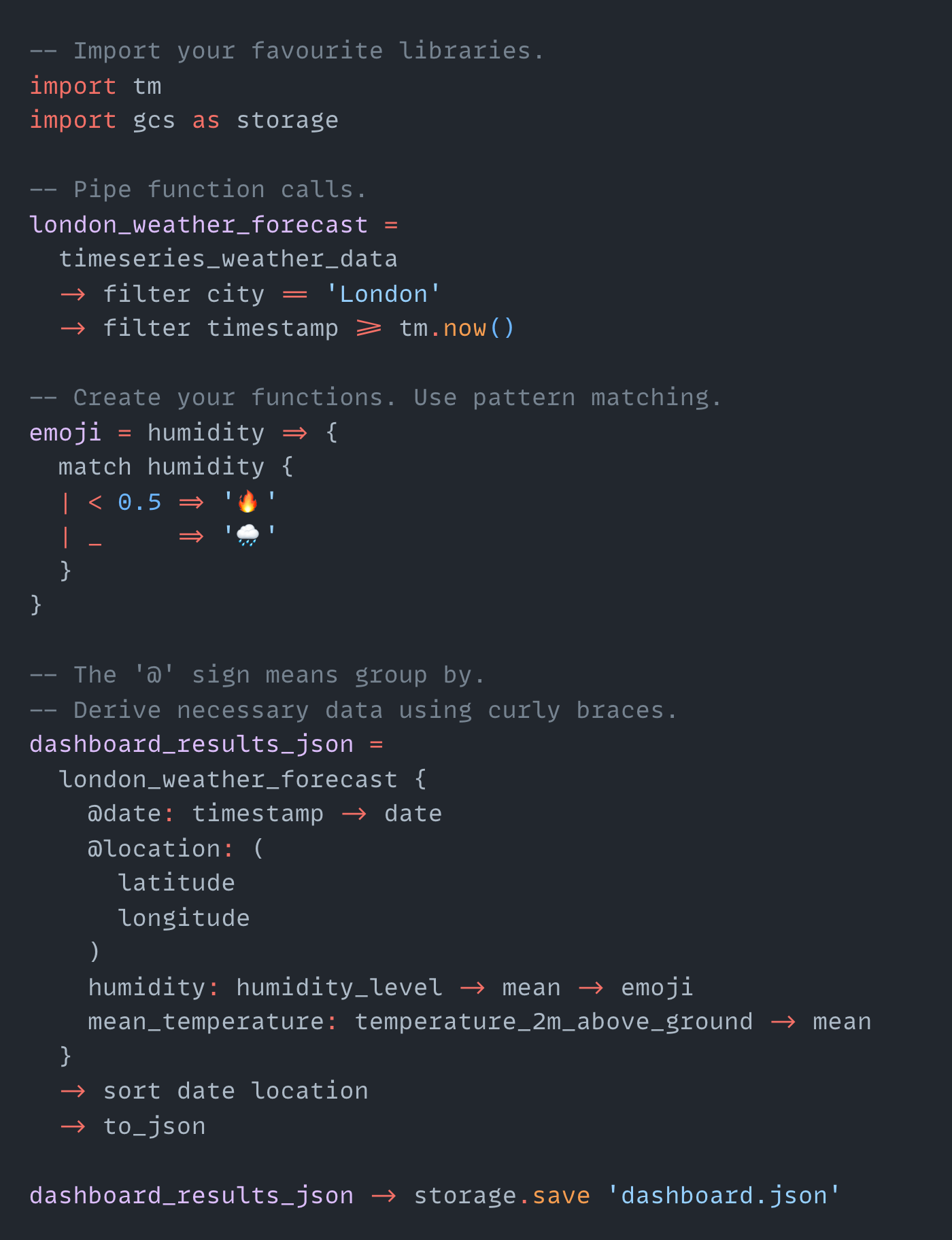
Please let me know if you have more ideas on how to improve it!
I started experimenting to figure out whether it’s feasible to implement such a thing, and if so, what would it look like.
First of all, maybe we shouldn’t build another language in the first place. Maybe it already exists (e.g. I found PRQL only a few days ago)? Maybe we could create a library or eDSL. How people are gonna be adopting it? All of these questions are important. I’ll share my thoughts and discoveries in the follow-up posts.
The frontend part (from code into AST) is more-less clear for me. I’ve re-written the scrappy prototype six times lol.
💡 Strongly recommend this video (Scott Wlaschin) parser combinators.
I’m a bit stuck on the backend side of the compiler. So, I’m happy with all suggestions!
Distributed Backend
The big question is what should DreamQL will be compiling to?
One option is to transpile everything into SQL (e.g. BigQuery), the same way as PRQL or Logica do. That sounds like a good starting point. See https://github.com/ajnsit/languages-that-compile-to-sql.
But it would be nice to compile it into something more low-level, skipping the SQL step. So the distributed query engine could optimise everything well and execute.
I’m looking for something like LLVM or WASM-style IR, but for distributed systems. Do you know anything like that?
One really promising programming framework (kudos Andrei Kashin for recommending it) is a Differential Dataflow (built on top of the Timely Dataflow). You can write any algorithm (e.g. Dijkstra) and it would be automatically parallelised. Materialize uses this for their real-time materialised views. The problem is that I’m not sure where I could run it - I would need to build the whole infra (say on top of GCP or AWS) to just run it. Maybe it’s not too hard though.
💡 Absolutely mind-bending Disorderly Distributed talk by Peter Alvaro.
UPD: there's a cool project hydro.run (see this video by the lead researcher from Berkeley Joseph Hellerstein on the rationale for this), which seems similar to Differential (thanks to Harvey Ellis for pointing out!)
I guess it could also be built on top of the Kafka Streams or Spark, or Dataflow by calling their APIs.
WASM as an extension language
Jamie Brandon recommends leaning on WASM as an extension language (see Against SQL). I think this is a brilliant idea because you can simply use your favourite library (say parsing strings) in your favourite language (say Python) from DreamQL.
Not sure how I could do that if I choose transpilation to SQL as a backend. In the case of BigQuery I would have to either:
- wrap this library into a Cloud Function (e.g. AWS Lambda) and then call it from the main code (extra API call)
- invoke WASM bytecode from JS UDF (you can do it!), kind of hacky and doesn’t scale well (one VM).
I think the same problem with other query engines like Postgres, etc.
Do you have any ideas about that?
Math framework under the hood
I would need to make sure that everything is self-consistent and proven.
I’m now diving into denotational semantics, relational algebra, etc. It would be nice to create something and prove it with coq or lean.
If you have any resources or ideas, that would be really helpful!
Name
Is DreamQL a good name? What would you call it? 🙂
Please help me improve my writing 🙏